はじめに
掲題のとおりですが、bqコマンドにてBigQueryのtable schemaを取得するときの自分用メモです。
bq showコマンド
schemaの取得は以下のように行います。
$ bq show \ --schema \ --format=prettyjson \ project_id:dataset.table > path_to_file
おわりに
bqコマンドがなにげに便利!!
掲題のとおりですが、bqコマンドにてBigQueryのtable schemaを取得するときの自分用メモです。
schemaの取得は以下のように行います。
$ bq show \ --schema \ --format=prettyjson \ project_id:dataset.table > path_to_file
bqコマンドがなにげに便利!!
GolangでBigQueryをざつに扱っています。
GolangでBigQueryのtableを作成時のSchema指定方法についての自分メモです。
この記事のサンプルコードは以下においてあります。
まずは基本的なtable create時のschema指定方法ですが、以下のように行います。
schema := /* 何らかの方法でSchemaを生成 */ metaData := &bigquery.TableMetadata{Schema: schema} t := client.Dataset(dataset).Table(table) if err := t.Create(ctx, metaData); err != nil { return err }
/* 何らかの方法でSchemaを生成 */ですが、
主には以下の3点があると思います。
- bigquery.Schema: field個別にSchema指定
- bigquery.InferSchema: struct + タグでSchema指定してみる
- bigquery.SchemaFromJSON: jsonファイルでSchema指定
ということで、以下では3つの方法を試してみます。
おもむろにサンプルコードを載せて解説は省きます。
fieldを個別にschemaを指定する方法です。
// client ctx := context.Background() client, err := bigquery.NewClient(ctx, projectID) if err != nil { return err } // schema schema := bigquery.Schema{ {Name: "id", Required: true, Type: bigquery.StringFieldType}, {Name: "data", Required: false, Type: bigquery.StringFieldType}, {Name: "timestamp", Required: false, Type: bigquery.TimestampFieldType}, } metaData := &bigquery.TableMetadata{Schema: schema} // create table t := client.Dataset(dataset).Table(table1) if err := t.Create(ctx, metaData); err != nil { return err }
structにbigqueryタグを指定し、bigquery.InferSchemaでschemaを作成する方法です。
type Item struct { ID string `bigquery:"id"` Data string `bigquery:"data"` Timestamp time.Time `bigquery:"timestamp"` } func createTableBySchema2() error { // client ctx := context.Background() client, err := bigquery.NewClient(ctx, projectID) if err != nil { return err } // schema schema, err := bigquery.InferSchema(Item{}) metaData := &bigquery.TableMetadata{Schema: schema} // create table t := client.Dataset(dataset).Table(table2) if err := t.Create(ctx, metaData); err != nil { return err } return nil }
jsonからSchemaを作成する方法です。
ファイルでなくても大丈夫ですが、この例ではファイルから読み込んでいます。
// client ctx := context.Background() client, err := bigquery.NewClient(ctx, projectID) if err != nil { return err } // schema path := "./schema/schemaSampleTable3.json" buf, err := ioutil.ReadFile(path) if err != nil { panic(err) } schema, err := bigquery.SchemaFromJSON(buf) metaData := &bigquery.TableMetadata{Schema: schema} // create table t := client.Dataset(dataset).Table(table3) if err := t.Create(ctx, metaData); err != nil { return err }
1つのポイントとして、nullable指定したいか?がキーになりそうです。
InferSchema(struct + タグ)指定ですが、
以下のようにnullable指定ができません。(というかやり方を調べたけどわからなかった)
2. bigquery.Schema: field個別にSchema指定のテーブル
3. bigquery.InferSchema: struct + タグでSchema指定してみるのテーブル
4. bigquery.SchemaFromJSON: jsonファイルでSchema指定のテーブル
そのため、nullを許容する場合はInferSchema以外が良さそうです。
なぜ今回調査をしたかですが、
「GolangでAPI(json形式)を受けて、その結果をBigQueryに保存したい」
という要件がありました。
この場合、APIの結果jsonとBigQueryのschemaのstructを一緒にできないか?と考えていました。
以下のような感じですね。
// APIの結果jsonとbigqueryのschemaを同じstructにしたい type Item struct { ID string `json:"id" bigquery:"id",` Data string `json:"data" bigquery:"data"` Timestamp time.Time `json:"time_stamp" bigquery:"timestamp"` }
ただし、nullableにできない(requiredになってしまう)という事に悩んだため、なくなく他の方法を探してみたという感じでした。
試したコードスニペットと参考にした公式です。
InferSchemaでNullalbeを指定する方法がわかったら知りたい...!!
GolangでBigQueryをざつに扱っています。
ローカルで開発するときはCredentialを指定しますが、
よく使う2つの方法を忘れがちなので自分メモ。
これは必ずやることとして、Credentialを作成します。
具体的には、以下2つを行います。
ここは本旨ではないので軽く触れる程度で省きます。
Service Accountの作成は、以下から行います。

Service Accountを作成したら、Manage keysを選択します。

次の画面にてADD KEY > Create new keyでkeyを作成します。
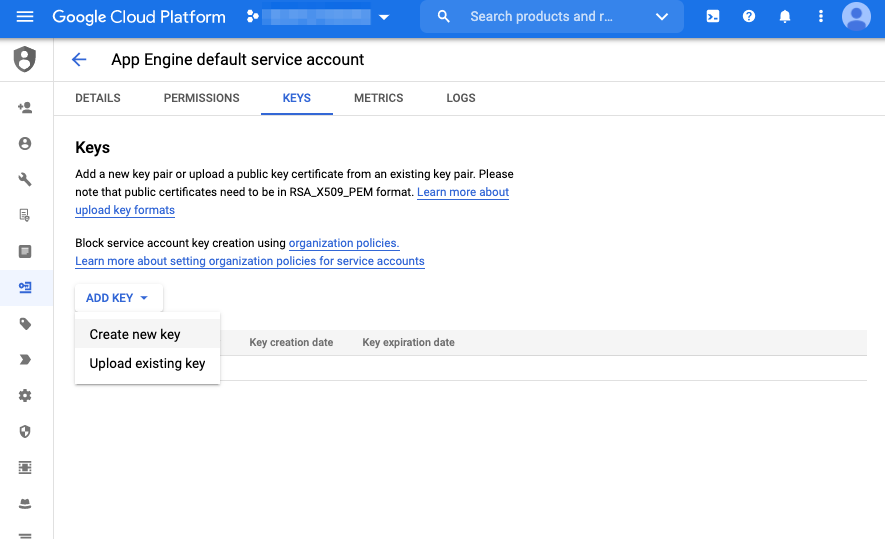
keyのタイプはjsonを選択してください。
このあとつかうCredentialsファイルになります。
ブラウザのダウンロードが始まるのでプロジェクトルートなどに置いてください。
この記事ではファイル名をkey.jsonとして保存しています。
上記で作成した、credentialsファイルを環境設定で指定する方法です。
まんまなので以下のコマンドを打つだけです。
$ export GOOGLE_APPLICATION_CREDENTIALS=./key.json
環境変数に設定しておくことで、bigqueryパッケージが環境変数に設定されていれば読み込んでくれます。
ただし、端末やPCの再起動で設定は消えてしまうので再設定が必要です。
こちらはプログラムに書くので再設定が必要ありません。
option.WithCredentialsFileを使ってcredensialsを読み込みます。
package main import ( "context" "fmt" "log" "cloud.google.com/go/bigquery" "google.golang.org/api/iterator" "google.golang.org/api/option" ) const ( key = "./key.json" projectID = "your-project" query = "select * from your-project.datasetName.tableName" ) func main() { ctx := context.Background() // client作成時にoption.WithCredentialsFileでファイルを読み込む client, err := bigquery.NewClient(ctx, projectID, option.WithCredentialsFile(key)) if err != nil { fmt.Printf("Failed to create client: %v", err) } defer client.Close() it, err := client.Query(query).Read(ctx) if err != nil { log.Printf("Failed to Read Query: %v", err) } for { var values []bigquery.Value err := it.Next(&values) if err == iterator.Done { break } if err != nil { fmt.Println("Failed to Iterate Query:%v", err) } fmt.Println(values) } }
試したコードスニペットをおいておきます
BigQueryは触っていて楽しいですが、golangから扱うときにちょくちょく面倒なことがありますね!
最近、BigQueryを触っています。
bqコマンドでコマンドラインからアクセスする際の自分メモです。
この記事で使うschemaやcsvファイルは以下のリポジトリにおいてあります。
* https://github.com/tweeeety/bq-command-sample
bqコマンドを使いはじめるにあたり確認です。
# bqコマンドのversionを確認 $ bq version This is BigQuery CLI 2.0.65 # projectを確認 $ gcloud config list [compute] region = asia-northeast1 zone = asia-northeast1-b [core] account = [your account] disable_usage_reporting = False project = [your project] Your active configuration is: [default] # 設定されていない場合はprojectを設定してから行う gcloud config set project [project name]
bqコマンドを使うには、cloud SDKをインストールする必要があります。
もしbq versionでコマンドが確認できない場合は、以下2点をやってみてください。
bqコマンドは大きく2つのフラグがあります。
- グローバル フラグ(共通フラグ): すべてのコマンドで使用可
- コマンド固有のフラグ: 特定のコマンドに適用される
詳しくは以下をご参照ください。
* コマンドライン ツール リファレンス
bqコマンドは予めフラグ(コマンドのオプション)を設定しておくことができます。
vim $HOME/.bigqueryrcに設定することで毎回オプションを指定せずに実行できるようになります。
グローバルフラグは直で、
コマンド固有のフラグは[command]でセクションをきって指定します。
$ vim ~/.bigqueryrc ---- vim ---- --credential_file="[path to file]/key.json" [query] --use_legacy_sql=false [mk] --use_legacy_sql=false -------------
特に使いそうなbqフラグにログとステータスを表示することものがあります。
うまくいかないときは設定してみると良いでしょう。
- --apilog=path_to_file: ログ・ファイルを指定
- --format=prettyjson: レスポンスをJSON形式で出力
# projectの確認
$ gcloud config list
bqコマンドでデータセットを作成します。
# 東京:asia-northeast1 にデータセットを作成 $ bq mk --data_location=asia-northeast1 bq_command_dataset Dataset '[your project]:bq_command_dataset' successfully created. # データセットの確認 $ bq ls datasetId -------------------- hogehoge fugafuga bq_command_dataset
bqコマンドにてテーブルを作成します。
schemaはjson形式にて記述したローカルのファイルを参照できます。
まずは、bqコマンドにてパーティション無しのテーブルを作成します。
$ bq mk \ --table \ --description "no partition table" \ --label hoge:fuga \ --schema ./schema.json \ hoge-project:bq_command_dataset.bq_command_no_pt_table
以下は、今回のschema.jsonのサンプルです。
BigQueryでのデータ型は以下を参照してください。
* 標準 SQL のデータ型
$ cat schema.json [ { "mode": "NULLABLE", "name": "employee_id", "type": "STRING" }, { "mode": "NULLABLE", "name": "name", "type": "STRING" }, { "mode": "NULLABLE", "name": "attendance", "type": "STRING" }, { "mode": "NULLABLE", "name": "partition_date", "type": "date" } ]
テーブルが作成されました。
consoleでもデータセットとテーブルが確認できます。
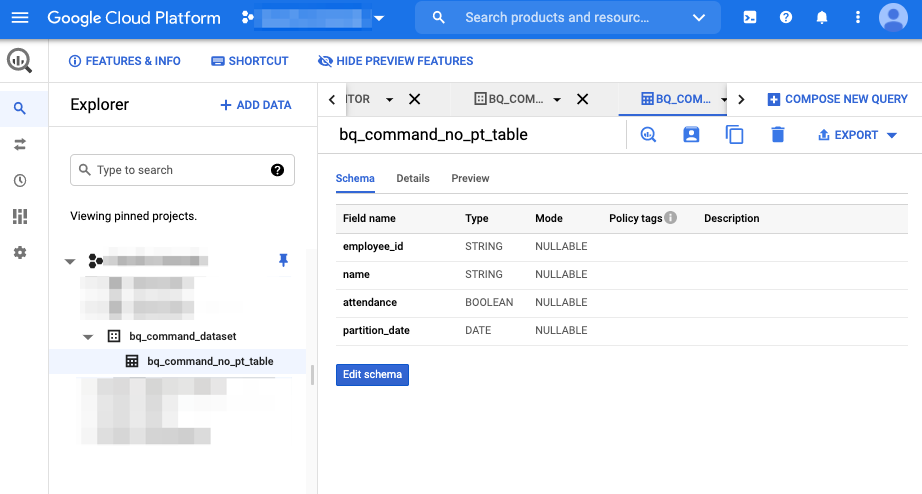
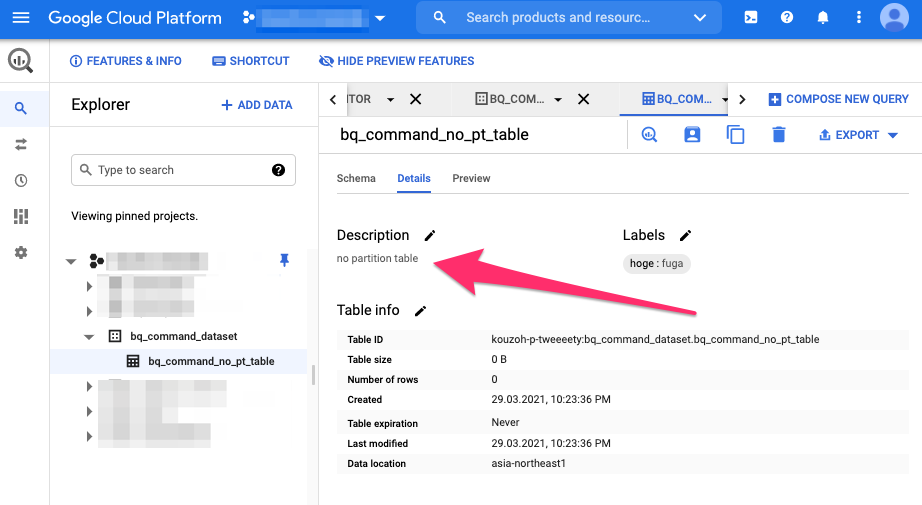
また、Detailsタブを開くとno partition tableと表示されてるのが確認できます。
次に、bqコマンドにてパーティション有りのテーブルを作成してみます。
$ bq mk \ --table \ --description hogehoge \ --schema ./schema.json \ --label hoge:piyo\ --require_partition_filter \ --time_partitioning_field partition_date \ --time_partitioning_type DAY \ hoge-project:bq_command_dataset.bq_command_pt_table
上記フラグはこんな感じの意味です。
--require_partition_filter: クエリを実行するパーティションを指定するためにWHERE句の使用を必須にする。--time_partitioning_type: DAY/HOUR/MONTH/YEARを指定。デフォルトDAY。--time_partitioning_field: パーティションに利用するカラムの指定
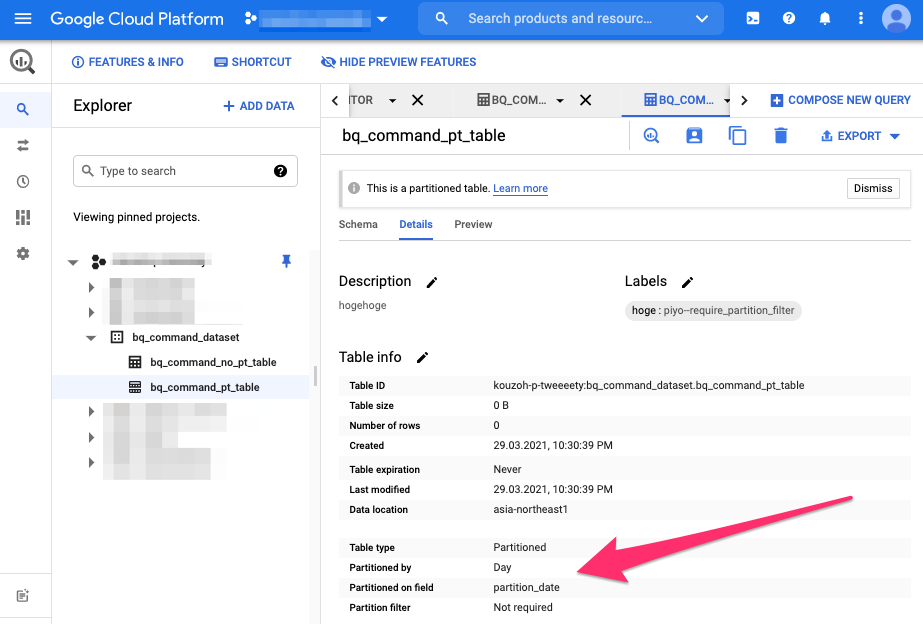
再度、consoleにて確認してみます。
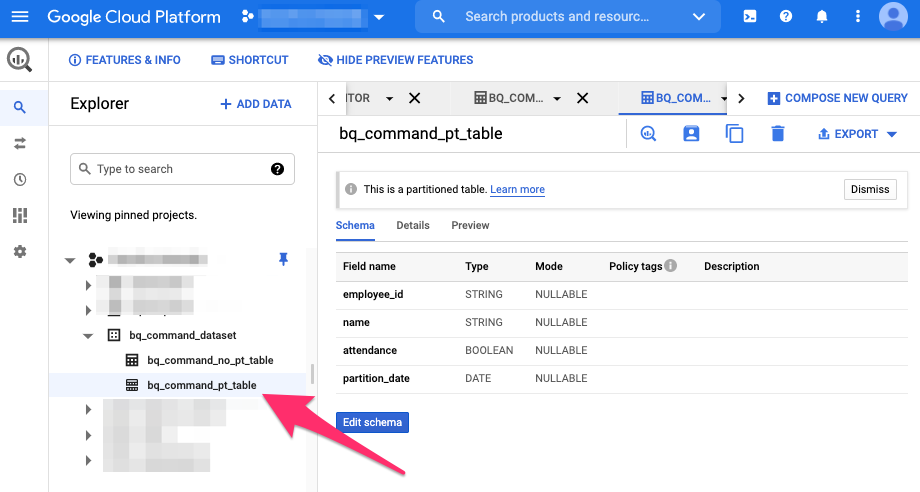
また、detailsタブをひらくと、今度はパーティションについての情報が表示されるのが確認できます。
consoleで確認しても良いですが、
毎回ブラウザを開いてはリロードで確認するのは面倒です。
そこで、コマンドラインにてbq showでテーブルの情報を確認します。
# dataset/table情報の確認 $ bq show \ --format=prettyjson \ hoge-project:bq_command_dataset.bq_command_pt_table { "creationTime": "1617024639811", "description": "hogehoge", "etag": "Q/5/uQq/jZawUbYZchsKvw==", "id": "hoge-project:bq_command_dataset.bq_command_pt_table", "kind": "bigquery#table", "labels": { "hoge": "piyo--require_partition_filter" }, "lastModifiedTime": "1617025188641", "location": "asia-northeast1", "numBytes": "168", "numLongTermBytes": "0", "numRows": "8", "schema": { "fields": [ { "mode": "NULLABLE", "name": "employee_id", "type": "STRING" }, { "mode": "NULLABLE", "name": "name", "type": "STRING" }, { "mode": "NULLABLE", "name": "attendance", "type": "BOOLEAN" }, { "mode": "NULLABLE", "name": "partition_date", "type": "DATE" } ] }, "selfLink": "https://bigquery.googleapis.com/bigquery/v2/projects/hoge-project/datasets/bq_command_dataset/tables/bq_command_pt_table", "tableReference": { "datasetId": "bq_command_dataset", "projectId": "hoge-project", "tableId": "bq_command_pt_table" }, "timePartitioning": { "field": "partition_date", "type": "DAY" }, "type": "TABLE" }
--schemaフラグをつけることで、スキーマ情報のみを取得することも可能です。
# schemaのみを取得 $ bq show \ --schema \ --format=prettyjson \ hoge-project:bq_command_dataset.bq_command_pt_table [ { "mode": "NULLABLE", "name": "employee_id", "type": "STRING" }, { "mode": "NULLABLE", "name": "name", "type": "STRING" }, { "mode": "NULLABLE", "name": "attendance", "type": "STRING" }, { "mode": "NULLABLE", "name": "partition_date", "type": "date" } ]
また、bq lsコマンドにてテーブルの一覧表示を確認できます。
$ bq ls \ --format=prettyjson \ hoge-project:bq_command_dataset [ { "creationTime": "1617024216763", "id": "hoge-project:bq_command_dataset.bq_command_no_pt_table", "kind": "bigquery#table", "labels": { "hoge": "fuga" }, "tableReference": { "datasetId": "bq_command_dataset", "projectId": "hoge-project", "tableId": "bq_command_no_pt_table" }, "type": "TABLE" }, { "creationTime": "1617024639811", "id": "hoge-project:bq_command_dataset.bq_command_pt_table", "kind": "bigquery#table", "labels": { "hoge": "piyo--require_partition_filter" }, "tableReference": { "datasetId": "bq_command_dataset", "projectId": "hoge-project", "tableId": "bq_command_pt_table" }, "timePartitioning": { "field": "partition_date", "type": "DAY" }, "type": "TABLE" } ]
__PARTITIONS_SUMMARY__メタテーブルを使うとパーティションに関する情報を取得できます。
$ bq query \ --use_legacy_sql=true \ 'SELECT partition_id FROM [bq_command_dataset.bq_command_pt_table$__PARTITIONS_SUMMARY__]' Waiting on bqjob_r3c1cbe985379d7e7_000001787e541b29_1 ... (0s) Current status: DONE +--------------+ | partition_id | +--------------+ | 20210101 | | 20210102 | +--------------+
これまで作成したデータセットとテーブルにデータを入れてみます。
今回はcsvですが、json形式でも大丈夫です。
# 01.csvを読み込む $ bq load \ --replace \ --source_format=CSV \ --schema=./schema.json \ hoge-project:bq_command_dataset.bq_command_pt_table \ ./source01.csv Upload complete. Waiting on bqjob_r78d80973f8b7b92c_000001787e35fed2_1 ... (0s) Current status: DONE # 02.csvを読み込む $ bq load \ --source_format=CSV \ --schema=./schema.json \ hoge-project:bq_command_dataset.bq_command_pt_table \ ./source02.csv Upload complete. Waiting on bqjob_r448ceceb57f44638_000001787e3639bc_1 ... (0s) Current status: DONE
--replaceフラグを追加すると、データの追加ではなく上書きになります。
delete or insertのような感じでしょうか。
bqコマンドにてselectする方法は主に2つあります。
まず最初に、生SQLでのbqコマンドでのselectです。
# bqコマンドに生SQL $ bq query \ --use_legacy_sql=false \ 'SELECT employee_id, name, attendance, partition_date FROM `bq_command_dataset.bq_command_pt_table`'
次に、SQL文を記載したSQLファイルを読み込んでのselectです。
SELECT employee_id,name FROM bq_command_dataset.bq_command_pt_table WHERE _PARTITIONDATE = "2021-01-01"
# bqコマンドにSQLファイルを読み込ませる $ bq query \ --use_legacy_sql=false \ < query.sql Waiting on bqjob_r4ce8a710bfc9077f_000001787de9e611_1 ... (0s) Current status: DONE +-------------+------+------------+----------------+ | employee_id | name | attendance | partition_date | +-------------+------+------------+----------------+ | 1001 | hoge | true | 2021-01-02 | | 1002 | fuga | true | 2021-01-02 | | 1003 | piyo | true | 2021-01-02 | | 1004 | fufu | false | 2021-01-02 | | 1001 | hoge | true | 2021-01-01 | | 1002 | fuga | true | 2021-01-01 | | 1003 | piyo | true | 2021-01-01 | | 1004 | fufu | true | 2021-01-01 | +-------------+------+------------+----------------+
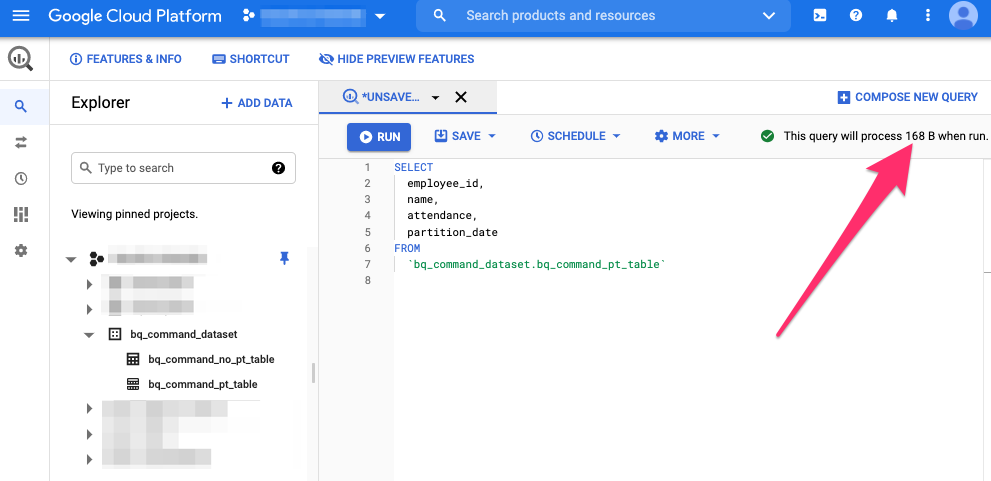
consoleからパーティションを指定したSQLで容量が変わるかを確認してみます。
まずは、パーティションの指定無しSQLから。
168Bと表示されているのがわかります。
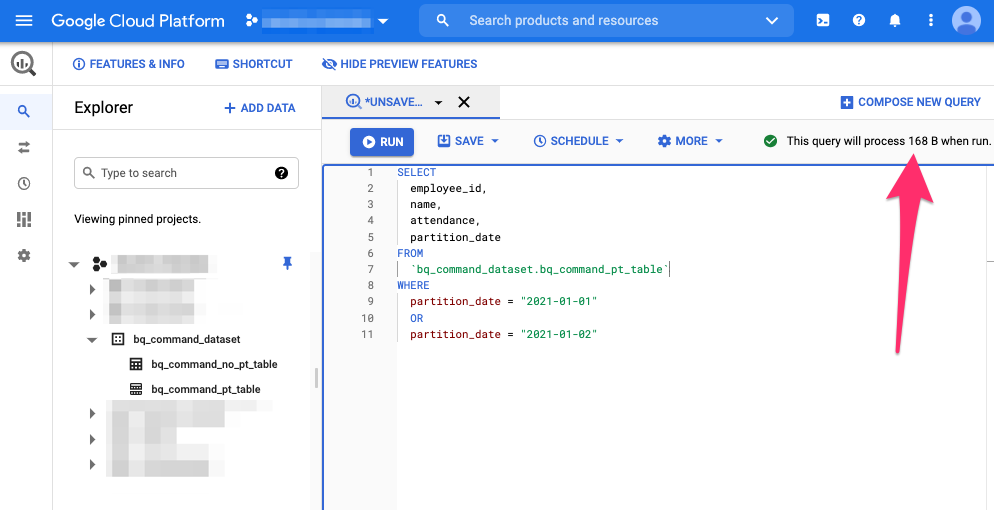
次に、パーティションを2つとも指定したSQL。
こちらも168Bと表示されています。まぁそうですよね。
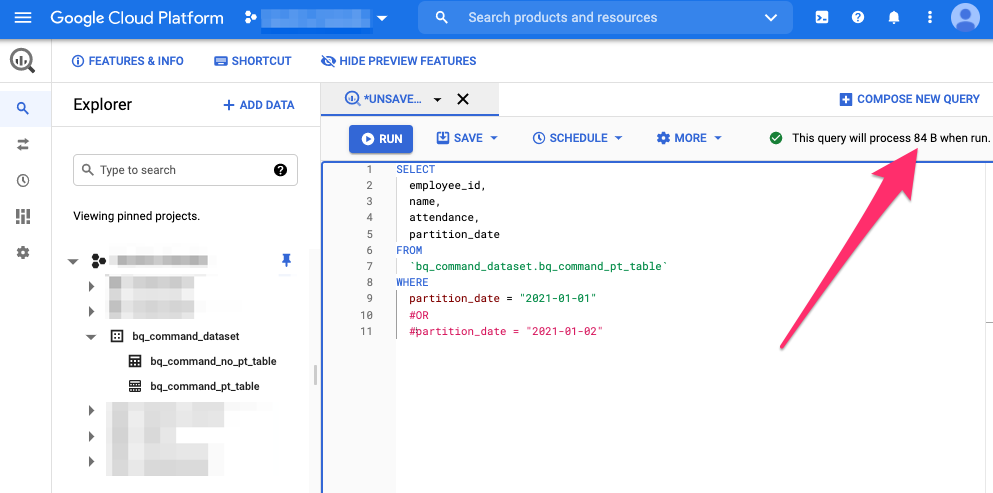
最後に、パーティションを1つだけ指定したSQL。
84Bと表示されました。指定カラムをそのままでも容量が減っている事が確認できます。
最後は、作成したtableを削除して終わりにします。
$ bq rm \ -f \ -t \ hoge-project:bq_command_dataset.bq_command_no_pt_table
bqコマンドが以外に便利だという事がわかりました!!enjoy!
表題のとおりですが、bqコマンドなんかを使用してDATE型の値をINSERTしようとすると以下のようなエラーになりました。
この原因と対処法について。
まず、INSERTするSchemaとdataです。
$ cat ./schema.json [ { "mode": "NULLABLE", "name": "employee_id", "type": "STRING" }, { "mode": "NULLABLE", "name": "birthday", "type": "STRING" }, { "mode": "NULLABLE", "name": "name", "type": "STRING" }, { "mode": "NULLABLE", "name": "partition_date", "type": "DATE" } ]
$ cat ./source.csv 1001,20210101,hoge,20210101 1002,20210303,fuga,20210101 1003,20210505,piyo,20210101 1004,20210707,fufu,20210101
つぎにINSERTです。
以下のようにエラーで怒られます。
$ bq load \ > --replace \ > --source_format=CSV \ > --schema=./schema.json \ > [your project]:bq_command_dataset.bq_command_pt_table \ > ./source.csv Upload complete. Waiting on bqjob_r187e4b6bf330eafd_000001781872232f_1 ... (0s) Current status: DONE BigQuery error in load operation: Error processing job '[your project]:bqjob_r187e4b6bf330eafd_000001781872232f_1': Error while reading data, error message: Could not parse '20210101' as DATE for field partition_date (position 3) starting at location 0 with message 'Unable to parse' Failure details: - Error while reading data, error message: CSV processing encountered too many errors, giving up. Rows: 1; errors: 1; max bad: 0; error percent: 0 - query: Could not parse '20210101' as DATE for field partition_date (position 3) starting at location 0 with message 'Unable to parse'
公式サイトに記載がありますが、YYYY-MM-DD形式が必須らしいです。
CSV データまたは JSON データを読み込む場合、DATE 列の値に区切りとしてダッシュ(-)を使用し、YYYY-MM-DD(年-月-日)の形式にする必要があります。
ということで、YYYY-MM-DDに変えてやるとINSERTが成功します。
# YYYYMMDDに変更する $ cat source.csv 1001,20210101,hoge,2021-01-01 1002,20210303,fuga,2021-01-01 1003,20210505,piyo,2021-01-01 1004,20210707,fufu,2021-01-01 # 成功する $ bq load \ > --replace \ > --source_format=CSV \ > --schema=./schema.json \ > [your project]:bq_command_dataset.bq_command_pt_table \ > ./source.csv Upload complete. Waiting on bqjob_rc9c3d4712ae526_00000178187453d6_1 ... (0s) Current status: DONE
BigQuery,とくにbqコマンドはオプションやルールがたくさんあるので公式を良く読むのが吉ですね!
GolangでGin(ジン)を5分で試すサンプルです。

本記事では以下の3要素のみ扱います。
- Golang
- Go Modules
- Gin
Ginは、Golangのフレームワークです。
歴史も長く、Golangで最も使われているフレームワークと言っても過言ではありません。
特徴は「薄い/早い/情報多い」と言った三拍子が揃っています。
Ginは数年前に職場で利用していました。
最近になり、あらためて触る機会が出たので再学習しています。
参考程度に、Golangのフレームワーク5つの人気比較を載せておきます。
| FW Name | Stars | Forks | Open Issues |
|---|---|---|---|
| Gin | 40.2k | 4.6k | 238 |
| beego | 25.5k | 4.9k | 746 |
| echo | 17.7k | 1.6k | 37 |
| kit | 17.5k | 1.8k | 59 |
| fasthttp | 13k | 1.1k | 34 |
ref: Top 5 Golang Frameworks in 2020
まずは、ローカルの環境を参考程度に載せておきます。
あくまでも自分の環境ですのであしからず。
$ sw_vers ProductName: Mac OS X ProductVersion: 10.15.7 BuildVersion: 19H524 $ go version go version go1.15.5 darwin/amd64
ディレクトリをつくり、go mod initでセットアップを行います。
# ディレクトリを作る $ mkdir go-gin-sample $ pwd /Users/tweeeety/go/src/github.com/tweeeety/go-gin-sample # go modulesを初期化する $ go mod init github.com/tweeeety/go-gin-sample $ cat go.mod module github.com/tweeeety/go-gin-sample go 1.15
Go Modulesが整っていればgo getするだけです。
正常であればgo.mod、go.sumのファイルが作成されているはずです。
$ go get github.com/gin-gonic/gin $ cat go.mod module github.com/tweeeety/go-gin-sample go 1.15 require github.com/gin-gonic/gin v1.6.3 // indirect
main.goにroutingとhtmlを表示するコードのみ書きます。
package main import ( "github.com/gin-gonic/gin" ) func main() { router := gin.Default() router.LoadHTMLGlob("templates/*.html") data := "Hello Go/Gin!!" router.GET("/", func(ctx *gin.Context) { ctx.HTML(200, "index.html", gin.H{"data": data}) }) router.Run() }
<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <title>Sample App</title> </head> <body> <h1>{{.data}}</h1> </body> </html>
特に問題がなければgo runで立ち上がります。
$ go run main.go [GIN-debug] [WARNING] Creating an Engine instance with the Logger and Recovery middleware already attached. [GIN-debug] [WARNING] Running in "debug" mode. Switch to "release" mode in production. - using env: export GIN_MODE=release - using code: gin.SetMode(gin.ReleaseMode) [GIN-debug] Loaded HTML Templates (2): - - index.html [GIN-debug] GET / --> main.main.func1 (3 handlers) [GIN-debug] Environment variable PORT is undefined. Using port :8080 by default [GIN-debug] Listening and serving HTTP on :8080 [GIN] 2021/02/15 - 19:57:13 | 200 | 452.175µs | ::1 | GET "/" [GIN] 2021/02/15 - 19:57:14 | 404 | 660ns | ::1 | GET "/favicon.ico"
ブラウザでhttp://localhost:8080/にアクセスすると以下のように表示されるのが確認できます。

かなり爆速で試せたんではないでしょうか?
今回のリポジトリは以下です。
https://github.com/tweeeety/go-gin-sample
薄いと開始が早くて良いですね!
routingもいろいろできます。そのあたりを含めたAPI Sampleは公式をご確認ください。
ひさびさにさくらVPSに入ってみました。
CentOSもまだ6ですが、それ以外もいろいろ古い。
gitだけでも新しくしておこうと思ったのでメモです。
# バージョン確認 -> 古い $ git --version git version 1.7.1 # tar.gzをダウンロードして解凍する $ cd /opt $ sudo wget https://mirrors.edge.kernel.org/pub/software/scm/git/git-2.9.5.tar.gz $ sudo tar xzvf git-2.9.5.tar.gz $ sudo rm git-2.9.5.tar.gz # make, make installでインストール $ cd git-2.9.5/ $ sudo make prefix=/usr/local all $ sudo make prefix=/usr/local install # バージョン確認 -> 新しい $ git --version
他のバージョンは以下から確認できます。 https://mirrors.edge.kernel.org/pub/software/scm/git/
ひさーーーしぶりにVPSに入ると何もかもが古い問題。。。