はじめに
最近、BigQueryを触っています。
bqコマンドでコマンドラインからアクセスする際の自分メモです。
この記事で使うschemaやcsvファイルは以下のリポジトリにおいてあります。
* https://github.com/tweeeety/bq-command-sample
アジェンダ
1. bqコマンドつかう前の確認
bqコマンドを使いはじめるにあたり確認です。
$ bq version
This is BigQuery CLI 2.0.65
$ gcloud config list
[compute]
region = asia-northeast1
zone = asia-northeast1-b
[core]
account = [your account]
disable_usage_reporting = False
project = [your project]
Your active configuration is: [default]
gcloud config set project [project name]
bqコマンドを使うには、cloud SDKをインストールする必要があります。
もしbq versionでコマンドが確認できない場合は、以下2点をやってみてください。
- cloud SDKをインストール
- Google Cloud Consoleでのプロジェクトの作成
- gcloudコマンドでのログイン
2. bqコマンドつかう前の設定
フラグ
bqコマンドは大きく2つのフラグがあります。
- グローバル フラグ(共通フラグ): すべてのコマンドで使用可
- コマンド固有のフラグ: 特定のコマンドに適用される
詳しくは以下をご参照ください。
* コマンドライン ツール リファレンス
.bigqueryrc
bqコマンドは予めフラグ(コマンドのオプション)を設定しておくことができます。
vim $HOME/.bigqueryrcに設定することで毎回オプションを指定せずに実行できるようになります。
グローバルフラグは直で、
コマンド固有のフラグは[command]でセクションをきって指定します。
$ vim ~/.bigqueryrc
---- vim ----
--credential_file="[path to file]/key.json"
[query]
--use_legacy_sql=false
[mk]
--use_legacy_sql=false
-------------
デバッグ フラグ
特に使いそうなbqフラグにログとステータスを表示することものがあります。
うまくいかないときは設定してみると良いでしょう。
- --apilog=path_to_file: ログ・ファイルを指定
- --format=prettyjson: レスポンスをJSON形式で出力
3. bqコマンドでprojectの確認
$ gcloud config list
4. bqコマンドでdatasetの作成/確認
bqコマンドでデータセットを作成します。
$ bq mk --data_location=asia-northeast1 bq_command_dataset
Dataset '[your project]:bq_command_dataset' successfully created.
$ bq ls
datasetId
--------------------
hogehoge
fugafuga
bq_command_dataset
5. bqコマンドでパーティション無し/有りtableの作成
bqコマンドにてテーブルを作成します。
schemaはjson形式にて記述したローカルのファイルを参照できます。
まずは、bqコマンドにてパーティション無しのテーブルを作成します。
$ bq mk \
--table \
--description "no partition table" \
--label hoge:fuga \
--schema ./schema.json \
hoge-project:bq_command_dataset.bq_command_no_pt_table
以下は、今回のschema.jsonのサンプルです。
BigQueryでのデータ型は以下を参照してください。
* 標準 SQL のデータ型
$ cat schema.json
[
{
"mode": "NULLABLE",
"name": "employee_id",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "name",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "attendance",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "partition_date",
"type": "date"
}
]
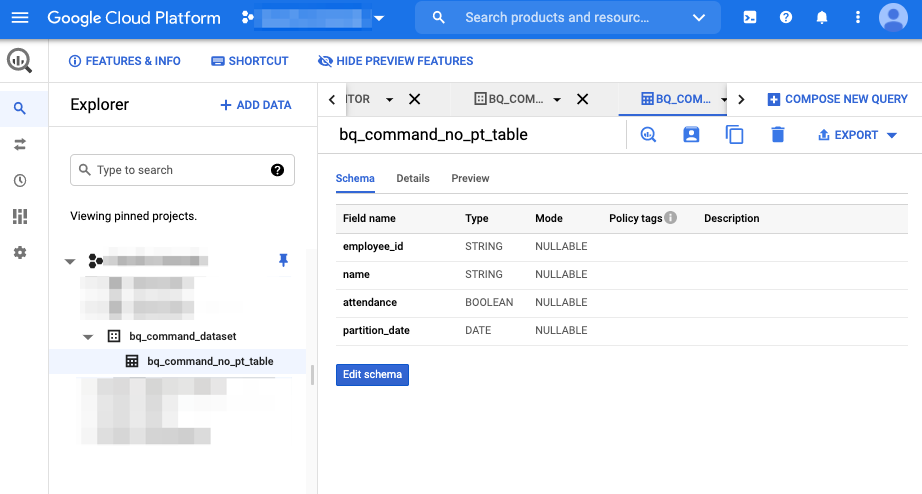
テーブルが作成されました。
consoleでもデータセットとテーブルが確認できます。
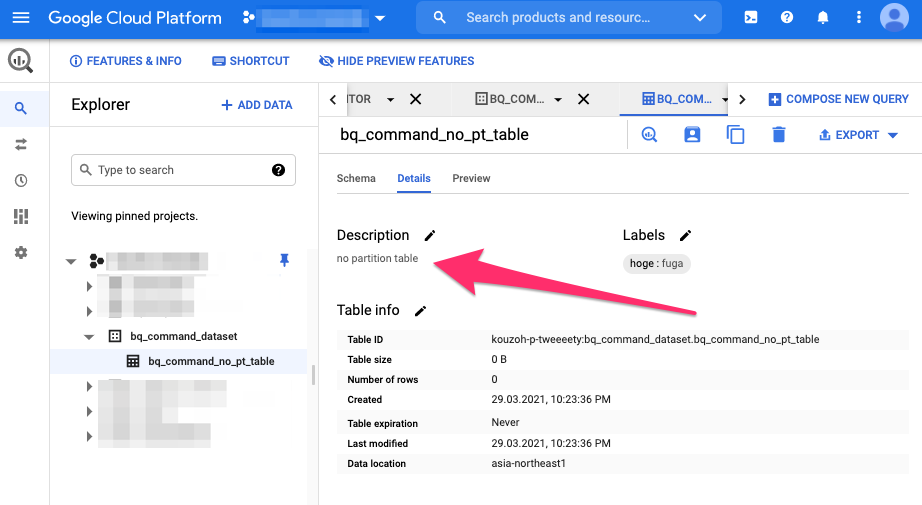
また、Detailsタブを開くとno partition tableと表示されてるのが確認できます。
次に、bqコマンドにてパーティション有りのテーブルを作成してみます。
$ bq mk \
--table \
--description hogehoge \
--schema ./schema.json \
--label hoge:piyo\
--require_partition_filter \
--time_partitioning_field partition_date \
--time_partitioning_type DAY \
hoge-project:bq_command_dataset.bq_command_pt_table
上記フラグはこんな感じの意味です。
--require_partition_filter: クエリを実行するパーティションを指定するためにWHERE句の使用を必須にする。--time_partitioning_type: DAY/HOUR/MONTH/YEARを指定。デフォルトDAY。--time_partitioning_field: パーティションに利用するカラムの指定
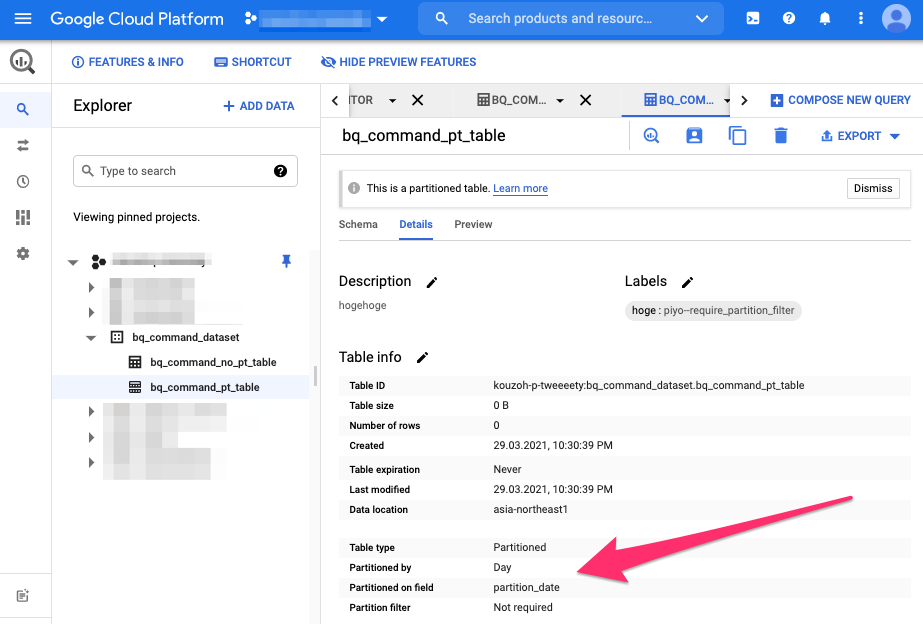
再度、consoleにて確認してみます。
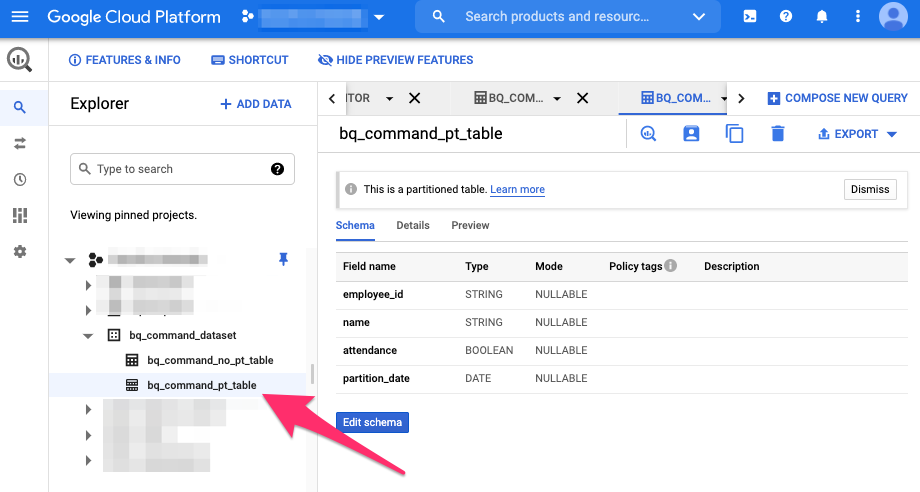
また、detailsタブをひらくと、今度はパーティションについての情報が表示されるのが確認できます。
6. bqコマンドでdataset/table/パーティション情報の確認
consoleで確認しても良いですが、
毎回ブラウザを開いてはリロードで確認するのは面倒です。
そこで、コマンドラインにてbq showでテーブルの情報を確認します。
$ bq show \
--format=prettyjson \
hoge-project:bq_command_dataset.bq_command_pt_table
{
"creationTime": "1617024639811",
"description": "hogehoge",
"etag": "Q/5/uQq/jZawUbYZchsKvw==",
"id": "hoge-project:bq_command_dataset.bq_command_pt_table",
"kind": "bigquery#table",
"labels": {
"hoge": "piyo--require_partition_filter"
},
"lastModifiedTime": "1617025188641",
"location": "asia-northeast1",
"numBytes": "168",
"numLongTermBytes": "0",
"numRows": "8",
"schema": {
"fields": [
{
"mode": "NULLABLE",
"name": "employee_id",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "name",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "attendance",
"type": "BOOLEAN"
},
{
"mode": "NULLABLE",
"name": "partition_date",
"type": "DATE"
}
]
},
"selfLink": "https://bigquery.googleapis.com/bigquery/v2/projects/hoge-project/datasets/bq_command_dataset/tables/bq_command_pt_table",
"tableReference": {
"datasetId": "bq_command_dataset",
"projectId": "hoge-project",
"tableId": "bq_command_pt_table"
},
"timePartitioning": {
"field": "partition_date",
"type": "DAY"
},
"type": "TABLE"
}
--schemaフラグをつけることで、スキーマ情報のみを取得することも可能です。
$ bq show \
--schema \
--format=prettyjson \
hoge-project:bq_command_dataset.bq_command_pt_table
[
{
"mode": "NULLABLE",
"name": "employee_id",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "name",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "attendance",
"type": "STRING"
},
{
"mode": "NULLABLE",
"name": "partition_date",
"type": "date"
}
]
また、bq lsコマンドにてテーブルの一覧表示を確認できます。
$ bq ls \
--format=prettyjson \
hoge-project:bq_command_dataset
[
{
"creationTime": "1617024216763",
"id": "hoge-project:bq_command_dataset.bq_command_no_pt_table",
"kind": "bigquery#table",
"labels": {
"hoge": "fuga"
},
"tableReference": {
"datasetId": "bq_command_dataset",
"projectId": "hoge-project",
"tableId": "bq_command_no_pt_table"
},
"type": "TABLE"
},
{
"creationTime": "1617024639811",
"id": "hoge-project:bq_command_dataset.bq_command_pt_table",
"kind": "bigquery#table",
"labels": {
"hoge": "piyo--require_partition_filter"
},
"tableReference": {
"datasetId": "bq_command_dataset",
"projectId": "hoge-project",
"tableId": "bq_command_pt_table"
},
"timePartitioning": {
"field": "partition_date",
"type": "DAY"
},
"type": "TABLE"
}
]
__PARTITIONS_SUMMARY__メタテーブルを使うとパーティションに関する情報を取得できます。
$ bq query \
--use_legacy_sql=true \
'SELECT
partition_id
FROM
[bq_command_dataset.bq_command_pt_table$__PARTITIONS_SUMMARY__]'
Waiting on bqjob_r3c1cbe985379d7e7_000001787e541b29_1 ... (0s) Current status: DONE
+--------------+
| partition_id |
+--------------+
| 20210101 |
| 20210102 |
+--------------+
7. bqコマンドでdataのinsert
これまで作成したデータセットとテーブルにデータを入れてみます。
今回はcsvですが、json形式でも大丈夫です。
$ bq load \
--replace \
--source_format=CSV \
--schema=./schema.json \
hoge-project:bq_command_dataset.bq_command_pt_table \
./source01.csv
Upload complete.
Waiting on bqjob_r78d80973f8b7b92c_000001787e35fed2_1 ... (0s) Current status: DONE
$ bq load \
--source_format=CSV \
--schema=./schema.json \
hoge-project:bq_command_dataset.bq_command_pt_table \
./source02.csv
Upload complete.
Waiting on bqjob_r448ceceb57f44638_000001787e3639bc_1 ... (0s) Current status: DONE
--replaceフラグを追加すると、データの追加ではなく上書きになります。
delete or insertのような感じでしょうか。
8. bqコマンドでdataのselect
bqコマンドにてselectする方法は主に2つあります。
- bqコマンドに生SQLを書く
- bqコマンドにSQLファイルを読み込ませる
まず最初に、生SQLでのbqコマンドでのselectです。
$ bq query \
--use_legacy_sql=false \
'SELECT
employee_id,
name,
attendance,
partition_date
FROM
`bq_command_dataset.bq_command_pt_table`'
次に、SQL文を記載したSQLファイルを読み込んでのselectです。
SELECT
employee_id,name
FROM
bq_command_dataset.bq_command_pt_table
WHERE
_PARTITIONDATE = "2021-01-01"
$ bq query \
--use_legacy_sql=false \
< query.sql
Waiting on bqjob_r4ce8a710bfc9077f_000001787de9e611_1 ... (0s) Current status: DONE
+-------------+------+------------+----------------+
| employee_id | name | attendance | partition_date |
+-------------+------+------------+----------------+
| 1001 | hoge | true | 2021-01-02 |
| 1002 | fuga | true | 2021-01-02 |
| 1003 | piyo | true | 2021-01-02 |
| 1004 | fufu | false | 2021-01-02 |
| 1001 | hoge | true | 2021-01-01 |
| 1002 | fuga | true | 2021-01-01 |
| 1003 | piyo | true | 2021-01-01 |
| 1004 | fufu | true | 2021-01-01 |
+-------------+------+------------+----------------+
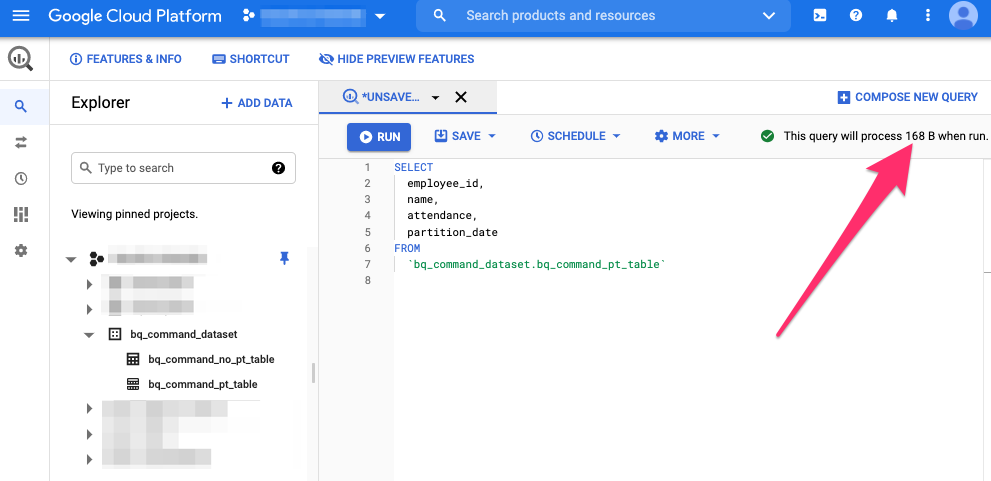
consoleからパーティションを指定したSQLで容量が変わるかを確認してみます。
まずは、パーティションの指定無しSQLから。
168Bと表示されているのがわかります。
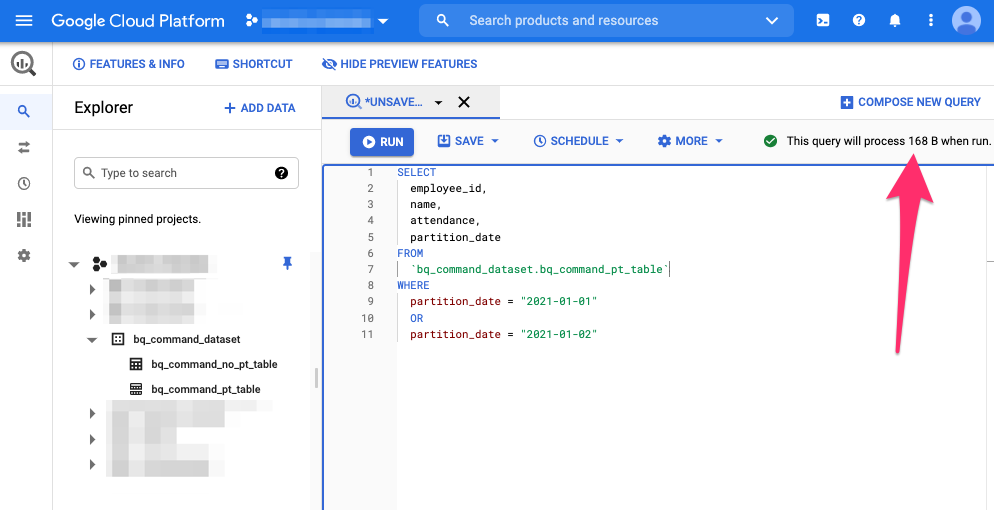
次に、パーティションを2つとも指定したSQL。
こちらも168Bと表示されています。まぁそうですよね。
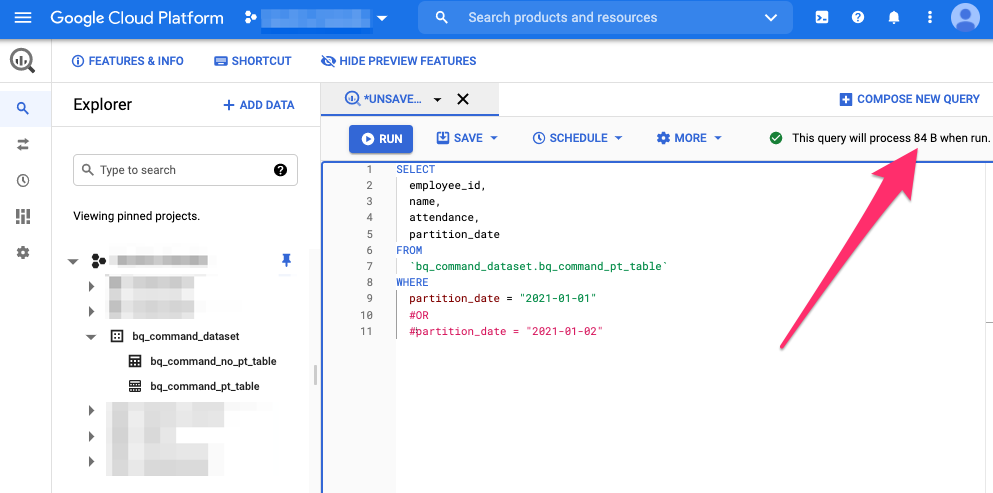
最後に、パーティションを1つだけ指定したSQL。
84Bと表示されました。指定カラムをそのままでも容量が減っている事が確認できます。
9. bqコマンドでtableのdelete
最後は、作成したtableを削除して終わりにします。
$ bq rm \
-f \
-t \
hoge-project:bq_command_dataset.bq_command_no_pt_table
参照
おわりに
bqコマンドが以外に便利だという事がわかりました!!enjoy!